个人学习内容笔记,仅供参考。
研究内容
该课题的主要目的是通过将二手房网站上的存量与已销售房源,构建一个二手房市场行情情况与房源特点的可视化平台。该平台通过HTML架构和Echarts完成可视化的搭建。因此,该课题的主要研究内容就是如何利用相关技术设计并实现这样的平台。
主要研究的内容如下:
- 相关理论和技术的研究。即对于构建这样的平台需要的理论知识与技术的研究,以及对于搭建该平台的框架认识与了解。并且考虑后续系统所可能的扩展。
- 数据爬取与清洗。通过Python开发语言、爬虫和页面解析软件包,结合链家网的页面结构和数据分布情况,对数据进行采集和数据清洗,为可视化提供有效的数据支撑。
- 可视化的需求分析。根据最终清洗的数据,从房源特点和客户关注度角度出发,详细分析平台所应当拥有的可视化模块。
- 平台的设计与实现。在对平台进行需求分析后,需要对平台进行整体的架构设计,应当考虑到如何用HTML和Echarts完成架构和不同可视化模块的设计
相关理论和技术
Selenium与Xpath爬虫模块
网络爬虫的核心是模拟用户行为,从目标网站自动提取数据。然而,链家网作为专业房产平台,为保护数据权益和服务器资源,设计了多层反爬机制,主要包括:动态内容渲染,用户行为检测,登录人机验证等。
针对链家网的反爬特性,本课题选择Selenium 自动化测试框架模拟真实浏览器行为,结合XPath 路径表达式定位动态内容。通过浏览器模拟,手动登录验证,用户行为模仿(滑动滚动、随机等待)规避爬虫风险。通过Xpath定位元素标签,获取页面元素内容。
Pandas数据清洗模块
爬虫采集的原始数据通常存在大量噪声,直接用于可视化会导致结论偏差。数据清洗的核心目标是通过缺失值处理、异常值修正、格式统一等操作,提升数据质量。
Pandas 是 Python 生态中专门用于数据处理的库,其DataFrame数据结构支持高效的表格数据操作,针对二手房数据清洗的核心功能包括缺失值处理、异常值检测与修正、数据转换与格式化。
Echarts数据可视化模块
可视化的核心目标是将清洗后的二手房数据(如价格、面积、区域分布)转化为直观的图表,帮助用户快速发现规律(如 “不同小区的在售房源数量与价格比对”)、识别趋势(如 “市场对房源关注的时间序列趋势”)。
ECharts 是百度开源的可视化库,支持 100 + 图表类型(柱状图、折线图、热力图、词云等),拥有丰富美观的图表类型、强大的动态交互功能、高度的定制化能力。
系统架构
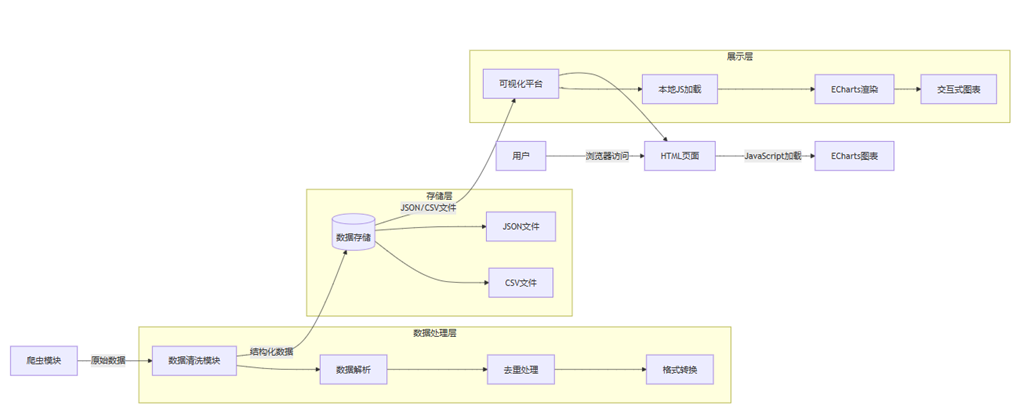
爬虫模块
爬虫模块用于采集链家网二手房成交数据,包含编号、小区等 12 项字段。技术实现采用 Selenium 驱动 Edge 浏览器,结合 lxml 解析 HTML 与正则表达式提取数据。反爬策略包括随机切换 User-Agent、模拟浏览器尺寸、设置滚动行为及请求间隔,遇验证码时支持人工干预。流程为初始化浏览器后访问列表页,解析房源列表项,提取单条数据并写入 CSV 文件。支持 1-100 页循环爬取,遇异常自动跳过并继续执行,确保数据采集连续性。
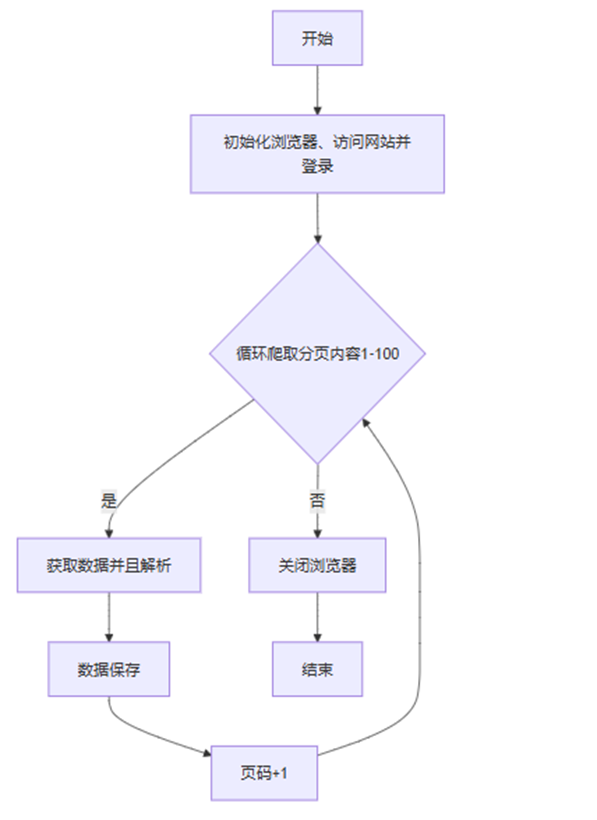
数据清洗和存储模块
以在售房源数据清洗存储为例
1.读取多城市在售数据,检测缺失值(填充NULL),删除重复记录,确保数据唯一性。
2.格式规范:提取面积、总价、单价的数值(正则匹配)转换为数值类型;发布时间转天数。
3.拆分户型为 “室”“厅”,对楼层、关注、发布时间、价格、朝向、面积户型等进行分类映射(如楼层等级 关注等级),生成新分析的分类字段。
4.分类存储:保存各城市 TOP50、全省 TOP100 房源(按关注人数排序)至 CSV,以 JSON 存储不同城市字段分类统计结果,辅助可视化。
5.数据合并:整合多城市数据,按指定列顺序排列,保存为全省在售数据集(CSV),支持跨城市综合分析。
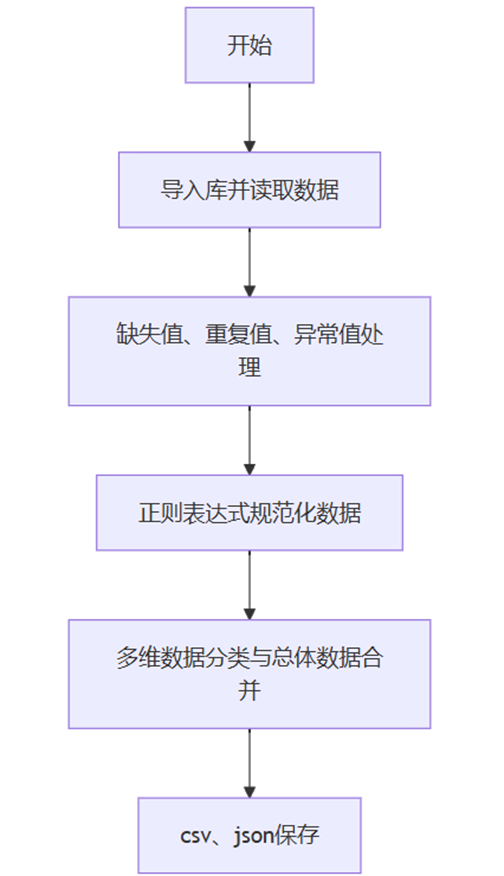
核心数据概览与多维交互模块
该需求是可视化平台的 “入口级功能” 与 “核心交互中枢”,通过全局数据概览快速建立用户对二手房市场的整体认知,通过多维筛选与可视化展示引导用户深入探索细分数据,目标是提升用户首次访问的留存率与使用时长,满足 “快速了解→精准筛选→深度分析” 的全链路需求。
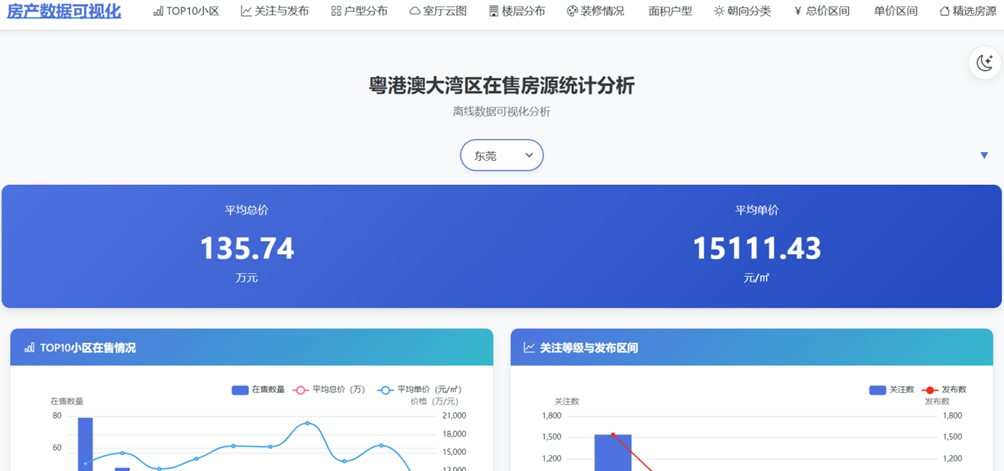
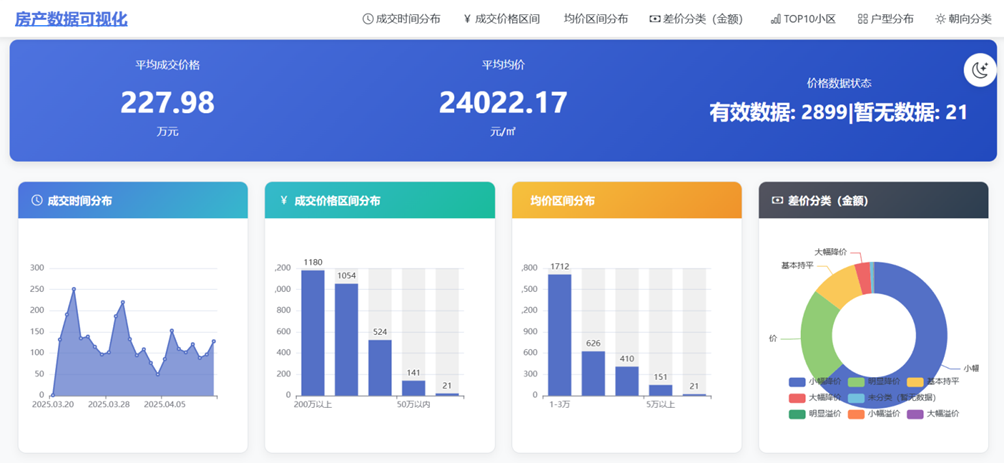
用户进入平台后 5 秒内通过概览数据(如 “深圳当前在售房源 12 万套,平均单价 6.8 万元 /㎡”)快速掌握市场热度;
数据呈现支持列表 / 地图 / 图表多视图切换,满足不同用户的信息获取习惯(如买家偏好价格区间找房,刚需用户偏好列表对比);
支持 10 + 维度交叉筛选(区域 / 价格 / 户型等),实时反馈匹配房源量(如 “南山区 + 3 房 + 500-800 万:匹配 235 套”),降低用户信息检索成本。
整体页面架构模块
展示层,以数据直观呈现 + 用户友好交互为核心,采用响应式布局适配 PC / 平板 / 手机多端,集成暗黑模式提升视觉舒适度,通过图表组件与交互控件实现数据深度探索。
- 响应式设计:基于 Bootstrap 网格系统实现布局自适应,大屏 4 列展示图表、中屏 2 列、小屏 1 列,配合媒体查询动态调整字体大小、统计卡片排列方向(水平→垂直)及图表容器高度,确保不同设备下的内容完整性。
- 暗黑模式:通过 CSS 变量定义双主题样式,亮色模式以浅灰为背景、深色为文本,暗黑模式切换为深灰背景、亮白文本;顶部固定切换按钮集成 Bootstrap 图标(月亮 / 太阳),点击后通过data-theme属性 +localStorage实现状态持久化,同时触发 ECharts 图表颜色动态适配。
- 动态交互:提供下拉式选择器,提供用户多城市数据切换展示,异步加载json文件内容。
逻辑层,聚焦数据整合 – 计算 – 渲染流程,通过模块化函数实现数据清洗、图表初始化及主题适配,确保前端展示与用户操作的高效联动。
- 图表智能渲染:initCharts函数统一处理 8 类图表(折线图 / 柱状图 / 饼图 / 词云等)的初始化逻辑,动态绑定城市数据(如成交时间生成折线图坐标),支持多图表类型的差异化配置(如词云图shape: ‘circle’、雷达图indicator动态计算最大值)
- 主题动态适配 :通过html元素的data-theme属性(light/dark)触发全局样式切换,图表组件通过getAttribute(‘data-theme’)实时获取主题状态,动态调整 ECharts 配置(如坐标轴文本色、背景色、词云颜色策略),确保视觉一致性。
数据层,以结构化存储 + 高效传输为目标,支持多城市、多维度成交数据的存储与分发,保障前端可视化的数据源可靠性。
- 数据存储:采用 JSON 文件存储各城市成交分类统计结果(如广州_成交分类统计结果.json),包含成交时间、价格区间、户型分布等 10 + 核心字段,支持快速读取与增量更新
- 数据流管理:通过静态文件服务提供数据访问接口,fetch请求直接调用目录下的 JSON 文件,避免复杂后端逻辑,降低部署成本
- 数据校验:JSON 文件遵循统一格式规范(如成交时间为{日期: 数量}对象、top10小区为包含小区/成交数量等字段的数组),确保initCharts函数可通用解析,减少前端数据清洗成本。
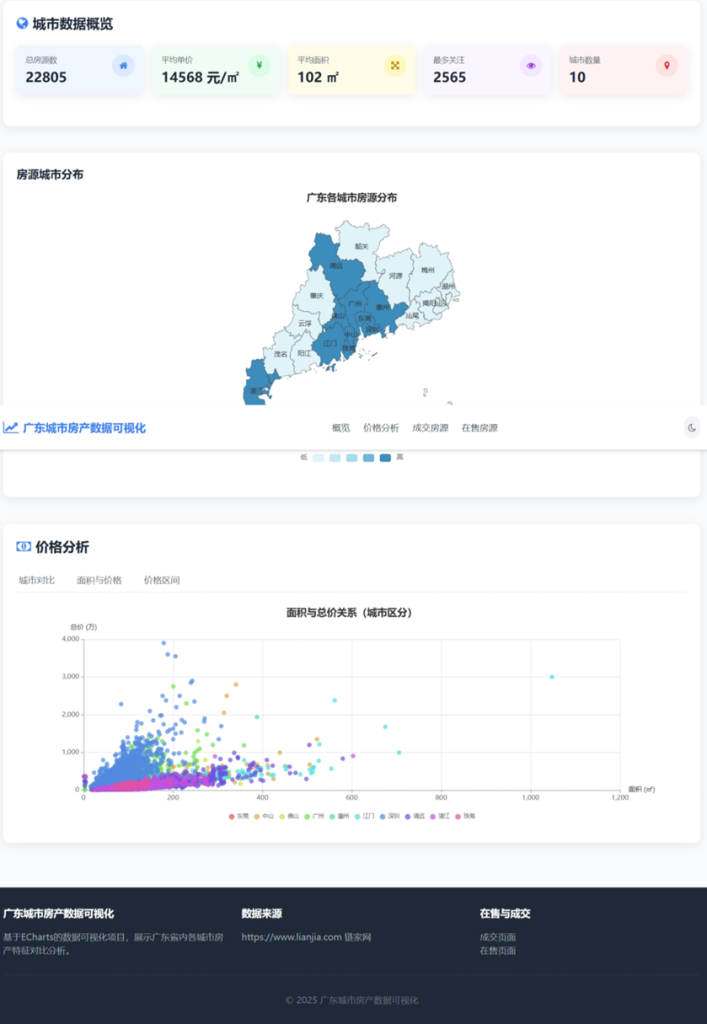
可视化结果
参考文章:https://blog.csdn.net/qq_46256922/article/details/119087591

