本项目聚焦于心理学专业网站 “心晴网” 的书籍数据,通过网络爬虫技术批量获取平台上的心理学书籍信息,构建包含书籍基本属性(书名、作者、出版社、简介、URL)、内容特征(标签、价格)、用户评价(收藏数、推荐数)等多维度的数据集。在数据获取基础上,运用数据清洗、文本挖掘、统计分析等技术手段,对心理学书籍的主题分布、用户偏好等进行简单剖析。最终通过交互式可视化工具,将分析结果以图表、选择器等形式直观呈现,实现对心晴网心理学书籍数据的系统化解读与应用。
项目源代码地址:https://gitee.com/rongwu651/pachong
设计思路
本项目采用 “数据采集 – 清洗治理 – 深度分析 – 可视化呈现” 的闭环式技术路线,以心理学专业领域知识为导向,结合自然语言处理与数据可视化技术,实现从原始数据到知识发现的全流程价值转化。具体设计思路如下:
数据采集层
目标网站解析和反爬策略
- 目标网站解析和反爬策略
通过浏览器开发者工具解析心晴网书籍列表页、详情页的 HTML 结构,识别动态加载组件(如价格内容通过JavaScript渲染),确定数据抓取入口;
同时,设置随机请求头(User-Agent、Referer)模拟真实浏览器行为、设置自动限速功能,动态调整请求频率,避免高频访问触发 IP 封禁。
- 多维度数据抓取
利用爬虫架构技术实现对目标网站页面架构内容获取,对于静态干净内容,直接通过定位标签元素解析获取数据内容。对于动态内容,结合网页渲染工具实时爬取数据内容。对于存在一定文本干扰的数据内容,采用正则表达式进行数据采集。
- 数据存储
对于爬取的数据,通过数据管道,根据数据类型,合理的存储在结构化数据库中。
数据清洗层
- 基础数据清洗
对关键字段(如标题、作者、出版社)的数据进行数据缺失值、重复值检查与处理。
- 文本数据处理
对于标签内容缺失的数据,通过 jieba 分词预处理文本,利用已分类书籍训练 TF-IDF 向量化器构建标签向量库,对未分类书籍文本向量化后计算与标签向量的余弦相似度,按阈值筛选高匹配标签,不足时用 TextRank 提取关键词补充,最终输出推荐标签并统计分布,实现标签智能推荐。
数据分析与可视化层
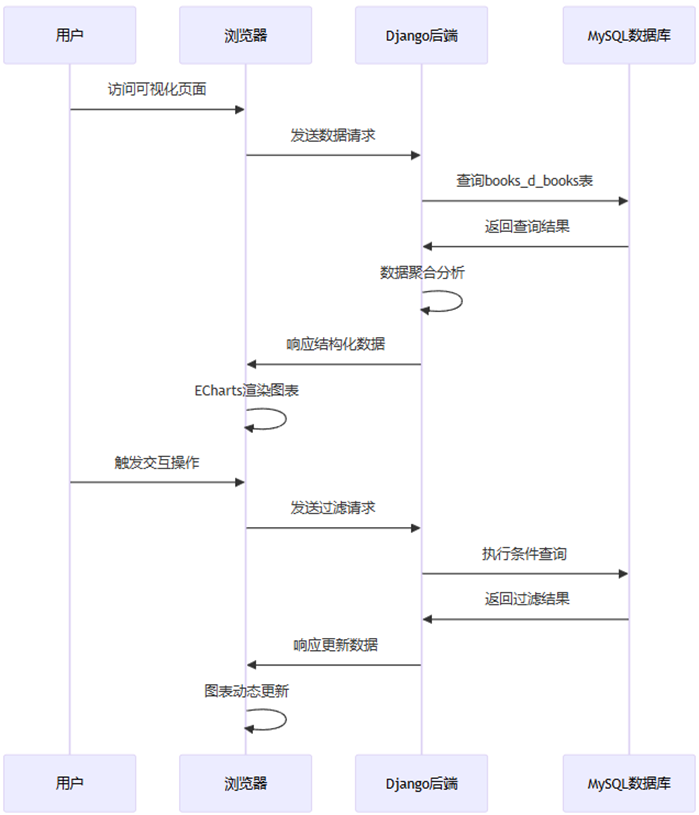
利用Django项目构建数据模型,并将清洗后的数据迁移至此。通过前后端分离架构设计,在后端实现多维度数据分析(主要以统计聚合为主)并输出结构化分析数据,前端采集后端数据并利用Echarts进行可视化图表渲染。同时设计选择器完成数据动态渲染。
技术选型
在技术选型中,爬虫、数据分析与可视化采用 Python 具有显著优势。Python 语法简洁易读,开发效率高,大量开源项目与第三方库降低开发成本,其与机器学习框架的无缝衔接,更能为数据全流程处理提供完整解决方案。
爬虫架构
| 技术 | 用途说明 | 优势特点 |
| Scrapy | 核心爬虫框架,负责爬取逻辑、调度、数据提取与存储 | 高效并发调度,组件化设计易扩展 |
| Splash | 动态渲染工具,处理 JS 加载的数据(如价格) | 支持 JS 渲染,多实例负载均衡 |
| Docker | 容器化部署 Splash 实例 | 环境隔离,快速管理实例生命周期(启停/删除),易扩展 |
数据处理模块
| 技术 | 用途说明 | 优势特点 |
| Pandas | 数据清洗、数据结构化处理 | 提高高效的数据处理接口方法,支持灵活数据转化 |
| jieba | 用于中文分词、关键词提取 | 支持自定义词库,提供多模式分词 |
| scikit-learn | 用于文本向量化和余弦相似度计算 | 集成标准化的特征工程工具和相似度算法,支持高效的文本特征提取与匹配 |
数据分析与可视化
| 技术 | 用途说明 | 优势特点 |
| Django | 后端Web架构,用于数据分析处理,向前端进行结构化数据输出 | 便携读取数据库内容,提供接口动态渲染数据内容。 |
| Echarts | 前端可视化库,将后端提供的结构化数据渲染为交互式图表 | 图表类型丰富,交互性能力强 |
数据库设计
数据表包含 9 个核心字段,覆盖书籍基础信息、用户交互数据及元数据,具体设计如下:
| 字段 | 属性 | 数据说明 |
| Id | Int | 主键,用于标识一组唯一的数据 |
| Title | Varchar | 书籍名标题 |
| Author | Varchar | 书籍所属作者 |
| Publisher | Varchar | 书籍发行出版社 |
| Price | Decimal | 书籍价格 |
| Tags | Varchar | 书籍所属标签类,存在多值 |
| Summary | Text | 书籍介绍内容 |
| fav_count | Int | 收藏该书籍的人数 |
| commend_count | Int | 推荐该书籍的人数 |
| url | Varchar | 爬取该书籍信息的原始网页链接 |
项目架构
爬虫设计
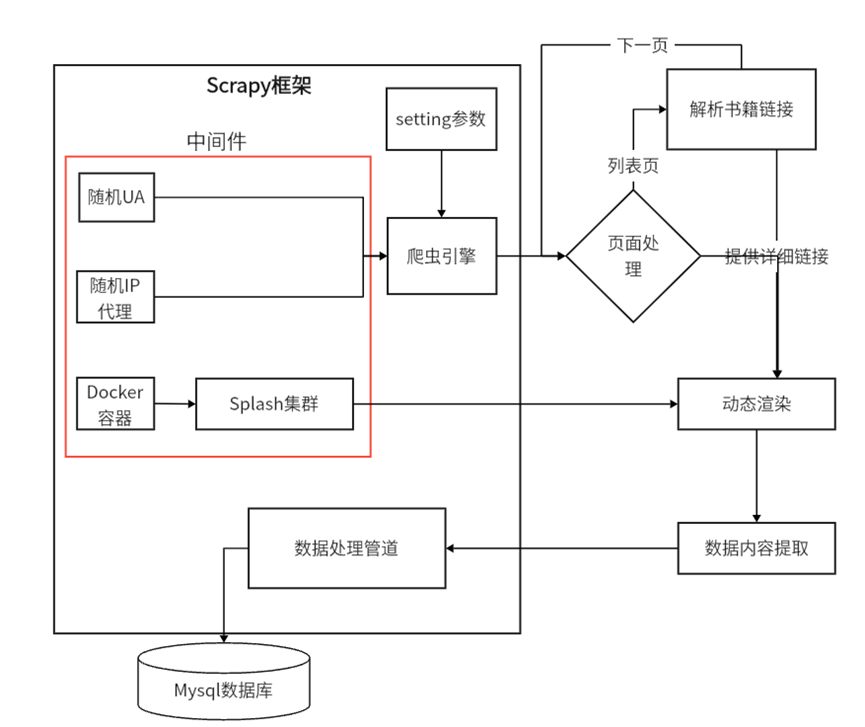
Scrapy 是一个功能强大的开源爬虫框架,它提供了许多内置的功能和组件,如请求调度、响应处理、数据提取、数据管道等,能够帮助我们快速构建高效、稳定的爬虫。因此我们只需要针对网站页面结构与业务需求,通过编写对应模块的代码,即可完成项目的搭建和运行。
利用Scrapy架构,结合网站布局结构,通过设计ixinqing_spider.py爬虫模块流程,通过分页爬取列表中的书籍链接(同时进行过滤重复和有效数据),进而对书籍详细页面进行数据内容获取并利用Xpath 标签定位解析元素内容。最后提取下一页链接,通过递归parse方法,实现全量列表链接爬取和详细数据内容解析与保存。
同时针对书籍详细页面存在需要动态渲染的数据内容(如价格),我们利用Docker构建多实例Splash集群,对目标详细页面内容进行自定义脚本注入,实现JavaScript渲染,提升并发处理能力的同时结合Xpath标签定位获取数据内容。
通过编写MySQLPipeline管道,连接数据库将爬取的详细页面内容存储在数据库中以定义好的数据表中。从而实现数据爬虫到数据存储全过程内容。
反爬虫策略
为缓解网站压力,防止IP封禁等其他因素导致爬虫过程出现异常,针对反爬虫策略处理主要通过,在middlewares.py中定义了随机状态头中间件,从settings.py的USER_AGENTS列表中随机选择用户代理,设置到请求头中。同理通过随机选择代理IP,设置到请求头中,避免单一IP爬虫被封禁。
同时,配置setting.py参数,例如下载延迟、总并发数、单域名并发数,控制每个请求的间隔和限制同一时间对目标网站的请求量。同时开启自动限速根据网站响应动态调整延迟,平衡爬取效率与反爬风险。
此外,利用多实例Splash集群,分散请求特征(如请求头,IP),降低反爬检测风险。针对爬虫返回出现的特定状态码,通过错误重试,应对临时反爬限制。
数据清洗
在对书籍数据处理中,完成对不同数据字段的重复值、缺失值筛选,异常值查看等基础检查和处理。此外,针对数据属性“标签”存在大量属于“未分类”的内容,且标签作为书籍分类的核心属性,直接影响数据的检索效率和分析价值。因此,我们将通过采用“文本向量化+语义相似度计算”的技术框架,提升数据的完整性和可用性。
- 将已分类书籍的标题和简介内容结合并进行预处理,使用TF-IDF算法计算每个词在文本中出现的频率,并结合该词在所有文本中的重要性(逆文档频率)来计算权重。
- 对于每个标签,我们将该标签下所有书籍的向量进行平均,得到该标签的特征向量。
- 对于每本未分类的书籍,我们计算其内容与知识库中各标签的相似度,按照相似度高低进行排序。结合关键词提取算法,综合生成推荐标签列表。
数据分析
保存数据清洗后的数据为CSV格式文件内容,同时构建Django数据模型D_Books,并将数据导入模型中。
通过Django前后端架构分离,我们在后端views.py实现数据分析,并将聚合分析后的数据生成为结构化数据输出至前端HTML页面中。
针对不同业务需求,我们根据字段完成以下内容:
- 统计与聚合
通过Django ORM关系映射,便携调用数据库内容字段,将查询结果按照作者字段进行分组,利用聚合函数统计出每个作者名下书籍的数量。同理聚合统计出出版社及其出版的书籍数量,并筛选出TOP10的数据。
- 数据范围划分
根据书籍价格的分布情况,定义多个价格区间(如0 – 10 元、10 – 20 元、20 – 30 元、30 – 50 元、50 – 100 元以及 100 元以上)。通过 Django ORM 的查询条件构建对象并分别统计每个区间内书籍的数量。
- 标签处理
利用 collections.Counter 统计处理后的标签列表中每个标签的出现频率,按照频率高低排序后选取前 15 个标签作为标签云数据。
- 相关性分析
关注收藏数与推荐数这两个指标之间的关系。通过将每本书的收藏数和推荐数进行配对组合,输出结构化数据至前端页面渲染。
可视化
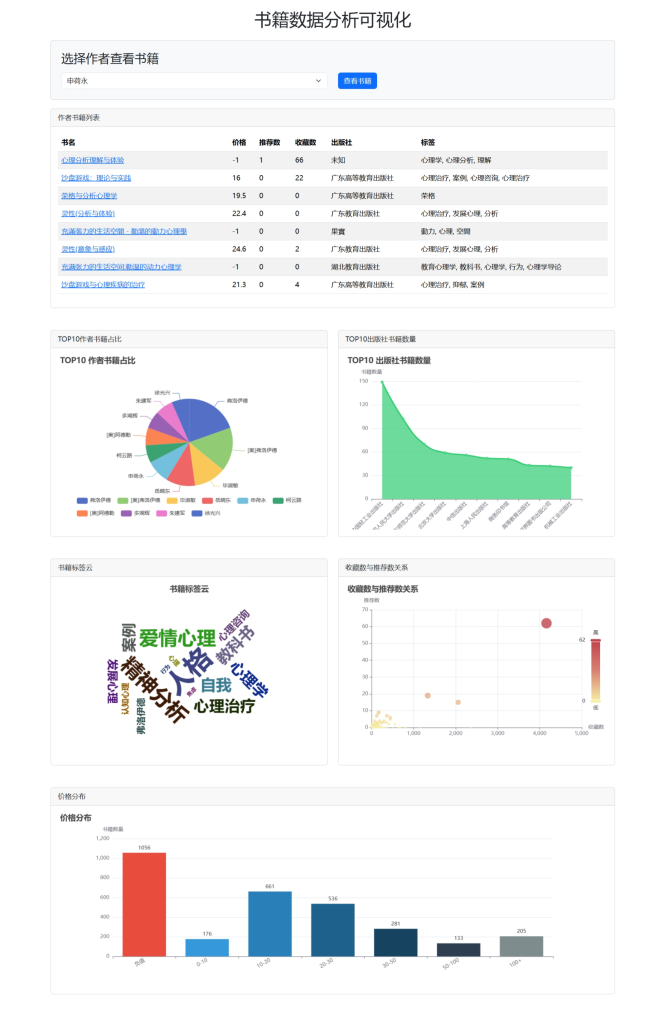
通过后端生成返回的数据结果,我们采用 ECharts 作为主要的可视化工具,它是一个基于 JavaScript 的开源可视化库,提供了丰富的图表类型和强大的交互功能,能够满足项目中各种复杂的可视化需求,如饼图、折线图、词云图、散点图、柱状图等,并且可以方便地与 Django 模板进行集成。
- TOP10 作者饼图 :直观地展示 TOP10 作者及其所占的书籍比例,通过饼图的扇形区域大小和颜色区分,让用户清晰地看到不同作者在书籍市场中的影响力和贡献度,方便用户快速了解哪些作者的作品更为受欢迎。
- TOP10 出版社折线面积图 :以折线面积图的形式呈现 TOP10 出版社的书籍数量变化趋势,折线图的平滑曲线和区域填充效果能够直观地反映出出版社之间书籍数量的差异和整体分布情况,帮助用户分析出版社的市场地位和发展态势。
- 标签云图 :利用词云图展示常见的书籍标签,标签的字体大小和颜色根据其出现频率和重要程度进行动态调整,突出了热门标签,使用户能够一目了然地了解当前书籍市场中流行的主题和趋势。
- 收藏数与推荐数关系图 :采用散点图展示收藏数与推荐数之间的关系,每个散点的大小根据推荐数进行动态调整,并通过视觉映射突出显示不同推荐数的点,为用户分析用户行为和推荐算法的效果提供了直观的依据。
- 价格分布柱状图 :通过柱状图直观地呈现不同价格区间内书籍的数量分布,柱状图的高度和颜色区分不同价格区间的书籍数量,使用户能够快速了解书籍价格的整体分布情况和各价格区间的书籍数量占比。
- 书籍选择器:提供出书数量TOP10的作者名字选择器,通过用户动态选择作者名称,动态渲染展示书籍详细信息列表
项目启动
爬虫架构
BS
│ requirements.txt #环境依赖
│ scrapy.cfg
│ __init__.py
│
├─BS
│ │ items.py #数据模型
│ │ middlewares.py # 中间件
│ │ pipelines.py #数据管道
│ │ settings.py #爬虫与架构配置
│ │ __init__.py
│ │
│ ├─spiders
│ │ │ ixinqing_spider.py # 爬虫主程序
│ │ │ __init__.py
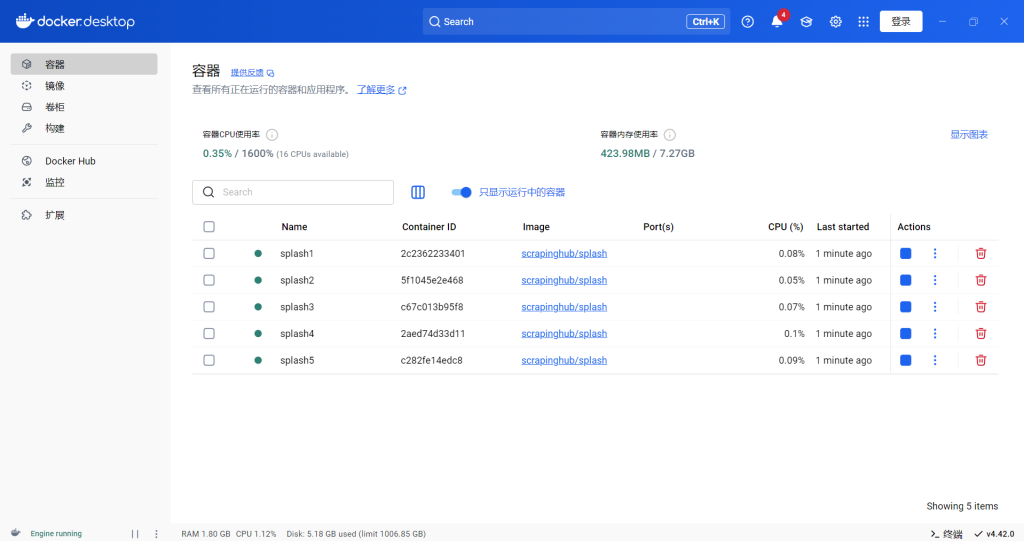
Windows docker启动splash集群,用于动态渲染
docker run -d --name splash1 -p 8050:8050 scrapinghub/splash --slots=5 --max-timeout=60
docker run -d --name splash2 -p 8051:8050 scrapinghub/splash --slots=5 --max-timeout=60
docker run -d --name splash3 -p 8052:8050 scrapinghub/splash --slots=5 --max-timeout=60
docker run -d --name splash4 -p 8053:8050 scrapinghub/splash --slots=5 --max-timeout=60
docker run -d --name splash5 -p 8054:8050 scrapinghub/splash --slots=5 --max-timeout=60
docker stats splash1 splash2 splash3 splash4 splash5 #监控状态
启动爬虫架构爬取数据
scrapy crawl ixinqing_spider -o 1.json #启动爬虫
# -o 1.json 用于测试爬虫是否有效
# 测试同时注意设置'DEPTH_LIMIT': 1 (分页循环爬取深度设置为1)
# 测试同时注释MySql数据写入管道 'BS.pipelines.MySQLPipeline'
数据爬取内容如下
数据清洗和Django分析与可视化
BookDjango
│ manage.py
│ requirements.txt
│
├─BookDjango
│ │ asgi.py
│ │ settings.py # 配置文件
│ │ urls.py #网页请求路径
│ │ wsgi.py
│ │ __init__.py
│ │
│
├─books #Django应用
│ │ admin.py
│ │ apps.py
│ │ models.py #数据模型
│ │ tests.py
│ │ views.py # 数据处理,输出结构化数据
│ ├─templates #网页代码
│ │ visualization.html│
├─Clear #数据清洗
│ data_clear.csv #清洗后的数据
│ data_clear.ipynb #清洗代码
│ import_data_toDjango.py #写入Django数据模型中
│
└─static #静态文件内容
├─css
│ bootstrap.min.css
│ tailwind.min.css
│
└─js
echarts-wordcloud.min.js
echarts.min.js
对于Django不熟悉的可以查看以下文章进行配置:
启动Django服务访问网页