前言:作为经营博客网站的一名大数据专业的大学生,个人博客不仅是展示技术见解、记录学习历程和分享生活感悟的重要窗口,更是连接志同道合者的数字桥梁。随着博客内容的丰富与访问量的逐步增长,理解“谁在访问”、“如何访问”以及“关注什么”变得至关重要。这些信息蕴含在服务器持续产生的访问日志中,是优化内容策略、提升用户体验、规划未来发展的核心数据资产。
因此,我将通过对网站访问者的请求访问进行数据收集,对实时流量趋势分析(如各国访问量、不同操作系统用户偏好、热门设备分布)的需求,设计并实现一套实时流量日志分析系统,通过技术手段实现数据采集、实时处理、多维度聚合及可视化展示,为运营决策提供数据支撑。用于数据内容涉及用户隐私,因此不提供数据集内容,个人学习内容笔记,仅供参考。
研究内容
本课题的核心目标是构建一个高效、实时的博客网站流量日志分析系统。该系统通过多维度数据采集、实时处理与聚合分析,实现对网站流量的深度洞察,帮助我快速掌握流量分布特征。课题的主要研究内容围绕如何利用大数据技术设计并实现高可靠、可扩展的实时分析系统,具体包括:
主要研究的内容如下:
- 针对大数据实时计算框架Kafka、zookeeper、storm,该如何设计系统架构,同时根据业务需求完成整套数据实时计算处理的实现。
- 系统的设计与实现。在对业务进行需求分析后,需要对系统进行整体的架构设计,应当考虑到如何用分层架构思想完成系统架构设计。之后,依据这些设计对系统进行落地实现。
- 核心功能实现细节与问题发现。针对各模块核心功能如何实现进行讲解,同时对开发过程中存在的问题进行简要概述问题与其解决方案。
系统架构设计
本课题的主要内容是采用 “数据采集→消息传输→实时处理→存储→查询” 的分层设计,核心组件包括 Kafka(消息队列)、Apache Storm(实时计算)、HBase(分布式存储)
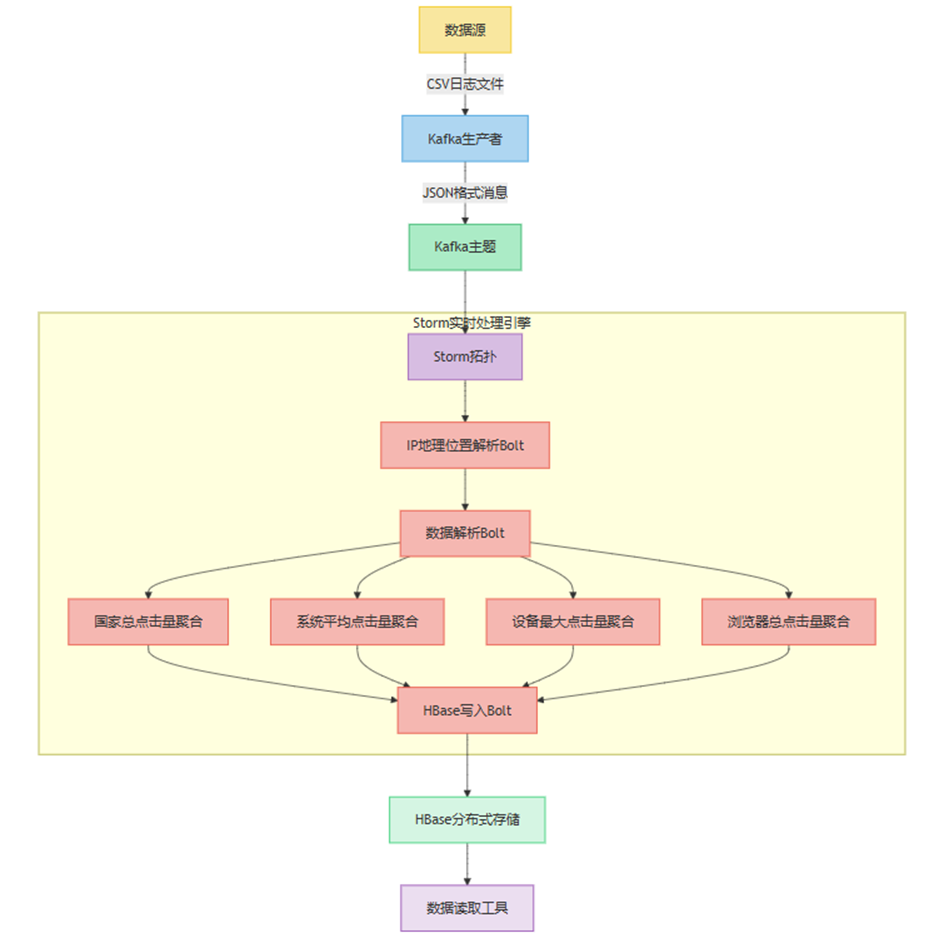
数据采集传输层
我们通过后台导出日志CSV文件并保存至项目中, 创建kafka生产者读取传输类CsvDataProducer,通过连接Kafka主题,读取并将CSV文件内容转为JSON格式,并按照日期作为分区依据写入到Kafka中。

计算Bolt层
IP定位Bolt
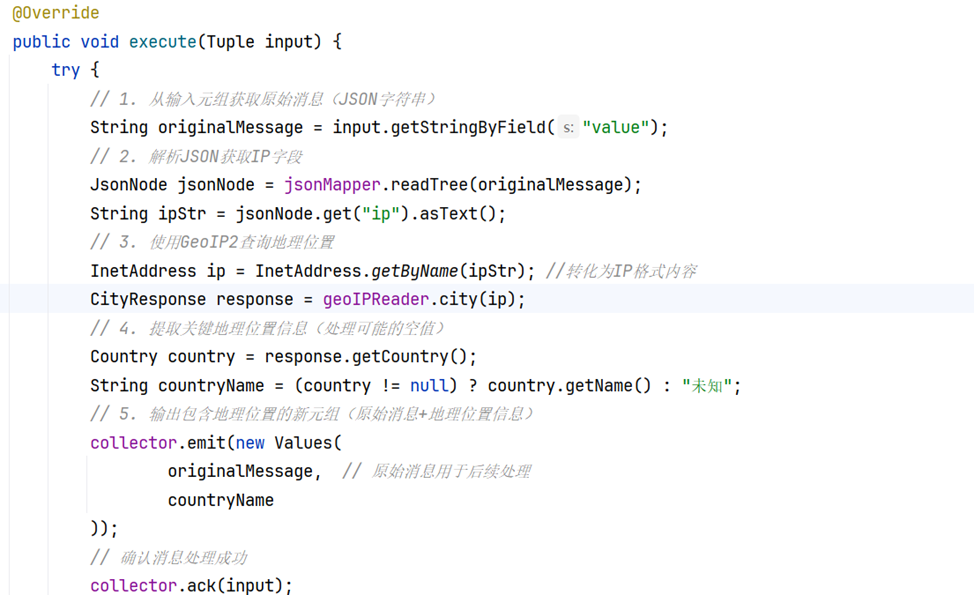
我们内置集成了功能强大的 MaxMind GeoIP2 数据库,它能提供准确的 IP 地理定位信息。将 IpLocationBolt 类作为第一层 Bolt,其主要职责是从 Kafka 消息队列读取信息。Kafka 消息队列接收的消息是 JSON 格式,IpLocationBolt 会使用 JSON 解析器从中提取 IP 字段。接着,借助 GeoIP2 数据库查询该 IP 对应的国家或地区信息。为确保数据处理的完整性和连贯性,它会将原始消息和查询到的国家或地区信息组合成新的元组输出,供后续的 Bolt 进行处理。
解析Bolt
我们把DataParseBolt 类作为第二层 Bolt。该 Bolt 接收来自第一层 IpLocationBolt 输出的元组,使用 JSON 解析器对输入元组中的 JSON 数据进行解析,从中提取出如日期、点击量、浏览器类型等关键数据。在日期处理方面,会把提取到的日期格式转换为统一格式,以方便后续的聚合和处理操作。最后,将处理后的数据重新组合成新的元组发射出去,以便后续不同类型的聚合 Bolt 进行针对性计算。
聚合Bolt
在第三层 Bolt 中,我们构建了 DailyCountrySumBolt、DailyPlatformAvgBolt、DailyDeviceMaxBolt 和 DailyAgentSumBolt 四个类,它们在整个数据处理流程中承担着关键的聚合任务。这些类会对第二层 DataParseBolt 解析出的详细数据进行进一步的聚合计算,从而满足不同的业务需求。具体如下:
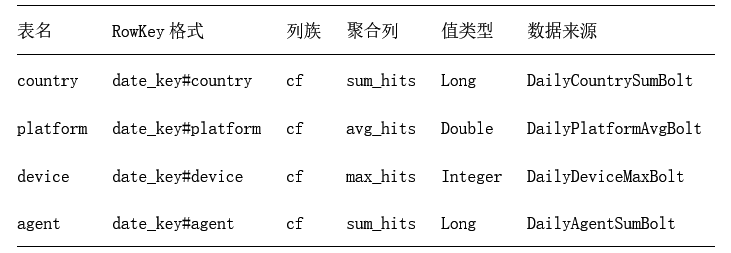
- DailyCountrySumBolt:使用 date_key#country 作为组合键,精准聚合每日每个国家的总点击量,能清晰呈现不同国家每天的业务活跃度。
- DailyPlatformAvgBolt:以 date_key#platform 作为组合键,采用双 Map 机制,分别记录总点击量和记录数,动态计算每日每个操作系统的平均点击量,有助于了解不同操作系统用户的平均点击行为。
- DailyDeviceMaxBolt:通过 date_key#device 键值,实时计算每日每个设备的最高点击量,方便识别特定日期下哪些设备的点击活跃度最高。
- DailyAgentSumBolt:以 date_key#agent 为维度,聚合每日每个浏览器的总点击量,可用于分析不同浏览器的用户使用情况。
存储层
存储层是整个实时分析系统的核心基础设施,负责持久化聚合结果并支持高效查询。本系统采用HBase作为主存储引擎,通过精心设计的表结构、写入策略和查询优化,满足多维度聚合数据的存储需求。以下是存储层模型的架构设计:
查询层
我们在HBaseDataReader通过构建多维度的数据查询引擎,封装了从HBase中读取四种聚合结果的统一接口。通过日期传参可获取当天的多维度数据内容。
核心功能实现细节
基于上述系统架构设计,本章将对其技术方案做出更详细的策划与实现,并阐述实现过程所遇的问题以及改进方案。本系统基于 Apache Storm 框架构建的流式数据处理系统,对从 Kafka 消息队列接收到的数据进行一系列处理,包括 IP 定位、数据解析、多维度数据聚合,最终将聚合结果存储到 HBase 数据库中。系统的主要业务目标是满足不同维度的数据分析需求,如每日国家总点击量、每日系统平均点击量、每日设备最大点击量和每日浏览器总点击量的统计。
数据生产
CSV数据读取与Kafka消息生成
通过系统架构设计说明结合数据特征与业务需求, CsvDataProducer 类负责从 CSV 文件读取数据并发送到 Kafka 主题。具体实现步骤如下:
- 配置 Kafka 生产者的属性,包括服务器地址与端口、序列化器、消息确认机制和重试次数。
- 使用 CsvReader 读取资源目录中的CSV文件,提取数据内容(包括日期、浏览器类型、操作系统类型、设备、IP 地址和点击次数)并转化为JSON格式。
- 创建ProducerRecord生产者,设置日期作为分区发送消息,并且处理发送结果。

数据处理拓扑
Kafka数据消费
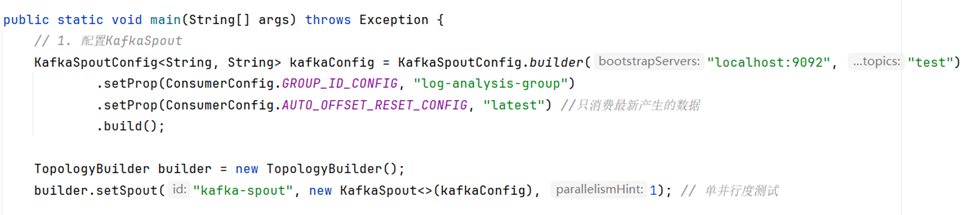
我们通过构建DataAggregationTopology 类配置了 KafkaSpout 来消费 Kafka 主题中的数据,构建“生产者——消费者”体系架构。
- 使用 KafkaSpoutConfig 构建 KafkaSpout 的配置,指定 Kafka 服务器地址、主题名称、消费者组 ID 和偏移量重置策略。
- 同时使用TopologyBuilder设置 KafkaSpout 作为拓扑的数据源。
IP地理位置解析
由于网站配置的IP地理位置解析器过旧,解析数据内容存在一定偏差,因此使用较新版本的GeoIP2 数据库,构建IpLocationBolt 类从 KafkaSpout 接收原始消息,解析 IP 地址并查询其地理位置。
- 通过初始化 GeoIP2 数据库读取器和 JSON 解析器,将上层交付的输入元组中获取原始数据内容,提取IP字段,通过GeoIP2查询并获取国家或地区名称信息。
- 最后输出包含原始消息和国家名称的新元组至下一层Bolt。
数据解析
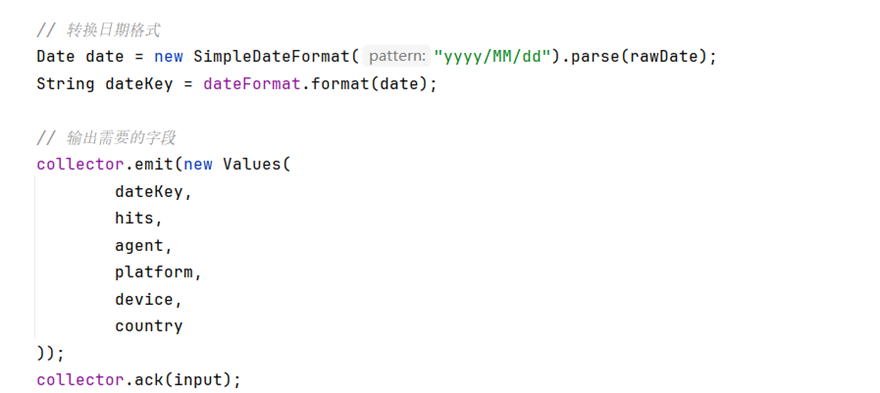
针对我们的业务需求,为后续数据聚合分析做准备,DataParseBolt 类将从 ip-location-bolt 获取原始消息,解析关键数据并输出需要的字段。
- 从输入元组中获取原始消息和国家名称,解析 JSON 并提取日期、点击次数、浏览器、操作系统、设备等字段。
- 将日期格式转化为yyyyMMdd,便于后续聚合分析。
- 输出扩展后的数据内容字段,交付给下层聚合。
数据聚合
根据系统架构和业务需求,数据聚合是整个系统的核心处理环节,主要负责对经过解析和处理后的数据按照不同的维度(日期和特定的业务维度,如国家、系统、设备、浏览器)进行聚合计算,得到相应的指标值(总点击量、平均点击量、最大点击量)。该环节由多个 Bolt 类协同完成,每个 Bolt 类负责处理特定维度的聚合任务。
- 状态维护。根据不同运算结果,使用不同的数值类型。同时使用Map数据结构,存储维护日期与不同维度组合的值(例如Map<String, Long>,date#country)
- 聚合逻辑。通过不同业务需求所需要的指标值,完成累加、平均计算、最大值比较等操作完成聚合操作与数值更新。
- 最后将聚合后的结果作为新的元组发送给下层进行处理。

以DailyAgentSumBolt每日浏览器总点击量为例:
- 通过业务需求,提取上层交付的元组中的关键字段。
- 构建日期+浏览器类型维度组合作为聚合键。
- 利用Map数据结构和计算逻辑,实现聚合(累加)内容更新。
- 最终将数据结果实时发送,完成实时更新。
数据存储与查询
Hbase写入
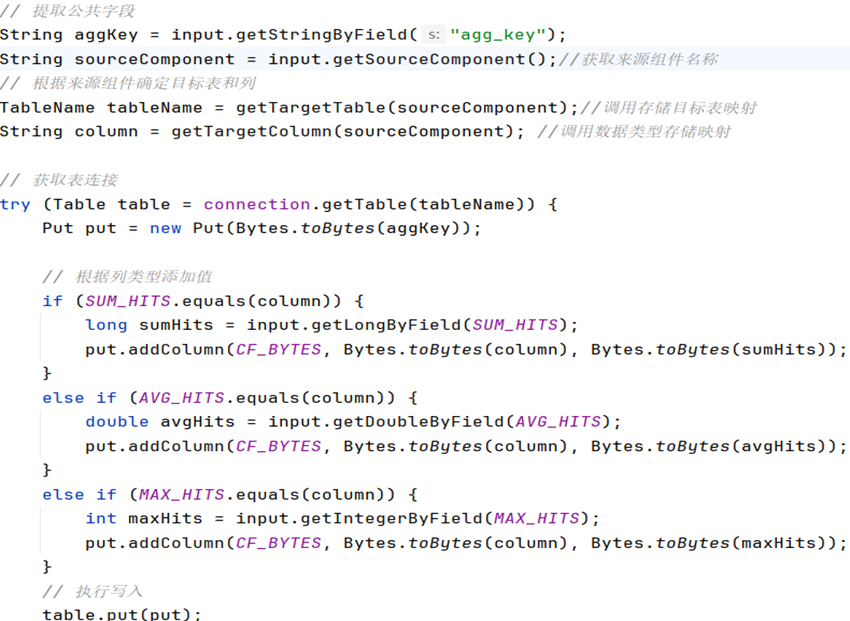
在存储层中,我们设计了对不同维度的数据内容存储的数据模型,通过上层交付的数据,HBaseWriteBolt 类将从各个聚合 Bolt 接收聚合结果,并将其写入 HBase 表:
- 创建Hbase连接和表名、列名常量字段。
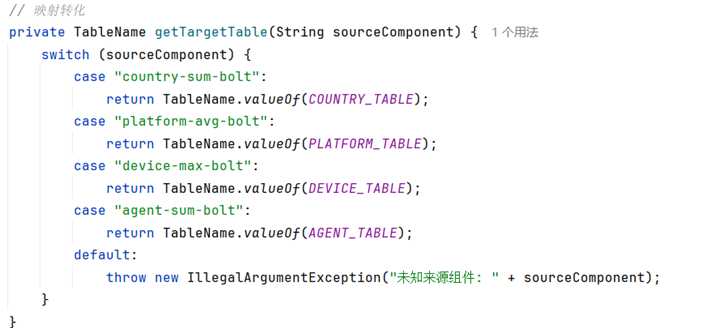
- 通过映射方法getTargetTable,根据源组件名称映射到对应的 HBase 表。
- 通过映射方法getTargetColumn,根据源组件名称映射到对应的列。
- 确认好映射结果目标,通过Put对象将数据写入相对应的Hbase表中
Hbase数据读取
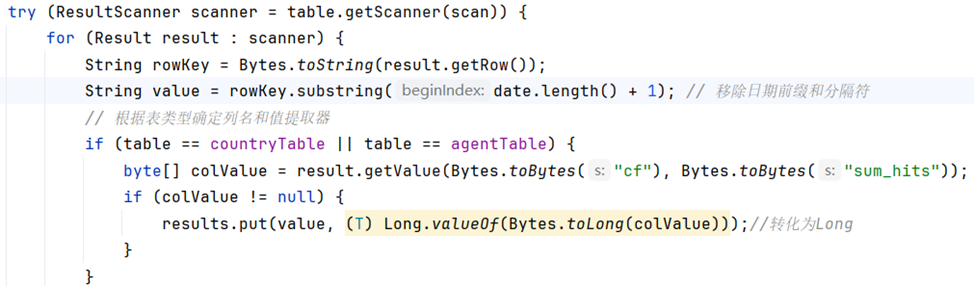
上一节我们通过将不同维度的数据存储在不同的数据表中,为方便读取不同表中的数据,通过编写一个泛类读取方法,接收表名和日期参数,获取对应结果值。
- 通过substring(date.length() + 1) 去掉日期前缀,提取维度值。
- 利用条件语句逻辑,根据表类型确认读取的数值类型。
- 最后通过接口调用,获取查询数据结果内容。


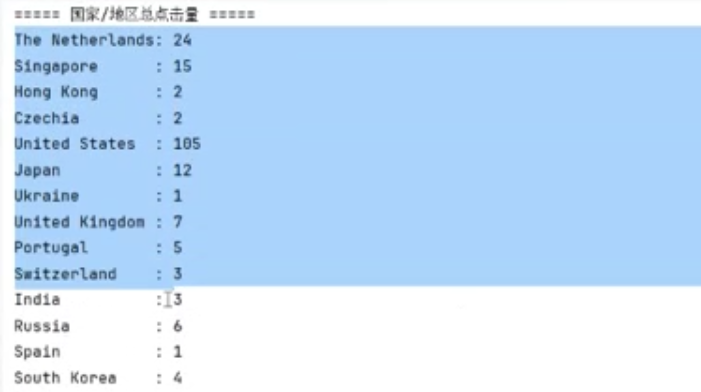
部分结果展示