
开发环境:Anaconda + Jupyter Notebook
数据分析概论
概论
数据是人们进行各种统计、计算、科学研究或技术设计等所依据的数值等原材料
在计算机科学领域,数据是指所有能输入计算机并能被计算机程序处理的符号的总称,是具有一定意义的数字、字母、符号和模拟量的统称
数据的形式:表现为数值、文字、图像、音频、视频、动画或计算机可以识别和处理的其他形式
数据的来源:
- 政府数据:统计数据、人口普查、经济年报
- 社会数据:商业数据、生产数据、媒体数据
- 个人数据:社交网络、个人消费
- 其他
数据按照表示形式分:结构化数据、半结构化数据和非结构化数据等
定义和分类
定义:
- 数据分析是运用适当的统计分析方法对收集来的大量数据进行分析、汇总,理解并消化它们,以求最大化地开发数据的功能,发挥数据的作用
- 数据分析是为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程它是数学与计算机科学相结合的产物
- 数据分析的目的是把隐藏在一批看似杂乱无章数据中的信息集中、茎取和提炼出来,找出研究对象的内在规律。在实际应用中,数据分析可帮助人们做出正确判断,以便采取适当行动
分类:
- 描述性数据分析:是指仅依赖数据本身的语义描述实现数据分析的方法。它的目的是描述数据的特征,找到数据的基本规律,对数据以外的事情不进行深入推论。这是数据分析的初级阶段
- 探索性数据分析:是为了形成值得假设的检验而对数据进行分析的一种方法,是对传统统计学假设检验手段的补充。探索性数据分析侧重在数据之中发现新的特征,通常比较灵活,讲究让数据自己说话。
- 验证性数据分析:验证性数据分析是在已有假设的基础上进行证实或者证伪。因此,在验证性数据分析之前往往已经有了预先设定的数据模型,数据分析过程中需要把现有的数据套入模型,通过数据分析来帮助确认模型的性能。
综述数据分析
- 有组织有目的地收集数据
- 采用适当的统计分析方法对收集到的数据进行分析、概括和总结
- 提取出有用信息
基本步骤
数据分析主要包括明确目的、数据收集、数据预处理、数据分析、结果呈现和撰写报告等几个阶段
数据预处理:
- 数据清理:数据清洗是对数据进行重新审查和校验的过程,它是发现并纠正数据中可识别错误的最后一道程序,目的在于删除重复信息、纠正存在的错误,处理无效数据和缺失值,并检查数据一致性等。
- 数据转换:将数据从一种表示形式变为另一种表示形式的过程。在数据转换中,数据的含义保持完全不变。数据转换一般发生在当前输入数据不能满足软件处理要求的情况下,通过对数据进行规格化操作,构成适合数据处理的描述形式。
- 数据集成:将来自多个数据源,包含不同格式和特点的数据在逻辑上或物理上有机地结合在一起形成一个统一的数据集合,以便为顺利完成数据分析工作提供完整的数据基础。
- 数据提取:从响应中获取数据分析所需数据的过程,它涉及从各种来源检索数据的操作。如果数据是结构化的,则数据提取通常在源系统内进行,常用的提取方法有完全提取法和增量提取法两种。
- 数据归约:在尽可能保持数据原貌的前提下,最大限度地精简数据量。当然,完成数据归约的必要前提是理解数据分析的目的并熟悉数据本身的特点及内容。数据归约主要有两个途径:属性选择和数据采样,分别针对原始数据集中的属性和记录进行操作。
数据分析:利用适当的分析方法和工具,对收集来的数据进行分析,提取有价值的信息,形成有效结论的过程。
Python基本语法与组合数据类型
基本语法:数据类型、运算符和表达式、控制结构、程序的循环结构、程序的异常处理、函数
组合数据类型:容器(列表、元组、字典、集合),字符串常用方法,推导式,迭代器对象和生成器表达式
Python基础为本课程的预修课程,不过多赘述,简要概括基本内容
在线预览:第二章 python基本语法 第三章 组合数据类型
本地数据采集和操作
文件的基本操作
建立文件对象就是建立文件与内存中数据存储区的联系读取数据是将文件中的数据读到内存的数据存储区写数据是将内存中数据存储区的数据按照一定的格式存入文件。
文件打开:Python提供内置函数open()创建文件对象
<文件对象名>=open(<文件名>,[<打开模式>],[<缓冲区设置策略>])
| 打开模式 | 功能 |
| ‘r’ | 只读方式打开文件(默认方式) |
| ‘w’ | 只写方式打开文件,如果文件存在,清除原来的内容 |
| ‘x’ | 创建一个新文件,只写方式打开文件,如果文件已存在则抛出异常 |
| ‘a’ | 只写方式打开文件,若文件存在,将要写入的数据追加在原文件内容之后 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式(默认方式) |
| ‘+’ | 读/写方式打开文件,用于更改文件内容 |
文件关闭:Python提供colse()关闭文件
文件读取:常用的方法包括read()、readline()、readlines()
f1=open('/path')
f2.read(8)#读取前8个字符
f1.read(10)#从当前位置继续读取10个字符
f1.readline()#从当前位置读取一行
f1.readlines(2)#读取相当于字节数的行数
f1.readlines()#读取文本文件中的多行数据,并返回列表
f1.close()#关闭文件
文件写入:常用函数有write()、writelines()
s1="Hello"
s2=["i","am","python"]
f1=open('/path','a+')
f1.write(s1)#写入数据,英文字符和汉字同等对待
f1.writelines(s2)
f1.close()
文件指针定位:每个打开的文件都有一个隐含的文件指针用于标识文件读写操作的当前位置。
例如:以包含“r”或“w”的方式打开文件则文件指针初始位置指向文件头部以包含“a”的方式打开文件则指针初始位置指向文件尾部。每当读写一定数目的字节,文件指针就后移相应的字节数。
Python中与文件指针相关的函数有tell()和seek()
#某文件内容
"""I LOVE PYTHON"""
f = open('/path')
f.read(3) #I L
f.tell() #使得指针下次读写操作在此(3)开始
f.read(10) #OVE PYTHON
f.seek(0) #使得指针从0开始
f.read(4) #I LO
使用with语句读取文件:使用with关键字可以确保代码发生异常后,能够正常调用close()
with open('/path') as f:
f.read
with open('/t1','r') as file_out,open('t2','w') as file_in:
file_in.write(file_out.read())
OS模板操作文件与目录
文件目录,又称为文件夹,是文件系统用于组织和管理文件的一种结构对象。Python的标准库os提供了操作文件与文件夹的函数,标准库os.path提供了路径判断、切分、连接及文件夹遍历的函数。
| 函数 | 说明 |
| remove(“filename”) | 删除指定文件flename;如果文件不存在,则抛出异常 |
| rename(“oldname”,”newname”) | 文件重命名 |
| getcwd( ) | 查看当前所在路径 |
| listdir(“path”) | 返回指定目录下的所有文件和文件夹,,返回列表类型 |
| mknod(“filename.txt”) | 创建空文件 |
| mkdir(“path”) | 创建目录 |
| mkdirs(“path”) | 创建多层目录 |
| rmdir(“path”) | 删除指定目录(只能删除空目录) |
| chdir(“path”) | 改变当前工作目录到指定路径 |
| 函数 | 说明 |
| abspath(“path”) | 返回指定路径的绝对路径 |
| basename(“path”) | 返回指定路径的文件名 |
| dirname(“path”) | 返回指定路径的目录名 |
| exists(“path”) | 判断给定的路径或文件是否存在 |
| isabs(“path”) | 判断给定的路径是否为绝对路径 |
| isdir(“path”) | 判断给定的路径是否为目录 |
| isfile(“path”) | 判断给定的路径是否为文件 |
| getsize(“path”) | 获得给定文件的大小 |
| getctime(“path”) | 获取路径创建时间 |
| getmtime(“path”) | 获取路径修改时间 |
| getatime(“path”) | 获取路径最后一次访问时间 |
JSON文件操作
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它采用完全独立于编程语言的文本格式来存储和表示数据,易于阅读和编写,同时也易于机器解析和生成,其简洁清晰的层次结构使得 JSON 成为理想的数据交换语言。
JSON文件:JSON数据保存为一个扩展名为「.json」的文件
JSON对象:JSON对象是一个由大括号“{}”括起来的无序键值对集合,键值对数据之间用逗号隔开,数据结构为{key1:value1, key2:value2,..}。其中键key描述对象的属性,一般采用整数或字符串类型;值value可以是任意类型的数据。
例如:{ "firstName":" John ","lastName":"Smith"}
JSON数组:JSON数组是用方括号“[ ]”括起来的一组数据元素,元素之间用逗号隔开,数据结构为[val1,val2,… valn,….]。JSON数组如同对象一样可以使用键值对,但还是使用索引更多一些。同样,数组元素可以是任意类型的数据。
例如:{ "people":[
{"firstName":" John ","lastName":"Smith"},
{"firstName":" TOM","lastName":"Smith"}
] }
常见的Python标准数据类型与JSON数据格式的转换对照
| Python数据类型 | JSON数据类型 |
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
JSON文件读写操作:导入json模板 import json
json.loads(str)函数将JSON数据格式转换为Python数据类型,这个过程称为解码
json.dumps(obj)函数将Python数据类型转换为JSON数据格式,这个过程称为编码
①读操作:常用函数有json.loads(str)、json.load()
import json
json.loads('{"a":97}') # {'a':97} loads(str)用于处理字符串
json.loads("{\"a\":97}")
filename='/path/filename.json'
wiht open(filename,r) as f:
f.data = json.load(f) # json.load()用于从指向的JSON文件类型对象将其数据转换为python的数据
②写操作:常用函数有json.dumps(obj)、json.dump()
参数dump(d, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None)
import json
# dumps(obj)函数只能实现字典类型对象转换
json.dumps({'a':123,'b':'ABC'}) # '{"a":123,"b":"ABC"}'
# json.dump()函数将生成的JSON数据保存到JSON文件中
filename='/path/filename.json'
list = [{},{},{},……{}]
with open(filename,mode='w',encoding='utf-8') as f:
json.dump(list,f)
CSV文件
CSV(Comma Seperated Values)是一种以逗号为分隔符的纯文本文件格式,通常用来存储电子表格数据。CSV文件的第一行通常为列名或字段名,其余的每行存储一个样本或记录。整个CSV文件由任意数目的记录组成,记录间以某种换行符分隔,每条记录由字段组成,字段间使用分隔符分隔,最常见的分隔符是逗号。CSV文件常用于不同程序之间的数据交换,特别是电子表格和数据库内容的导入导出操作。
CSV文件也是一种文本文件,完全可以按照普通文本文件的操作对CSV数据进行读写。
with open('/path/filename.csv','w') as f:
f.write('…………') #写入操作
with open('/path/filename.csv','r') as f:
s = f.read().split('\n') #读取操作
for i in s:
print(i)
使用CSV模块进行读写操作
①读操作:函数reader(csvfile),创建并返回一个可迭代的读对象,每次迭代以字符串列表的形式返回文件中的一行数据。
from csv import reader
with open('/path/filename.csv','r') as f:
lines = reader(f)
for line in lines:
print(line)②写操作:函数writer(csvfile),创建并返回一个可迭代的写对象,写对象支持writerow()和writerows()将数据写入目标文件。
from csv import writer
lines = [['1','98'],['2','90'],['3','88'],['4','70']]
with open('/path/filename.csv','a',newline = '') as f:
wr = writer(f)
for line in lines:
wr.writerow(line)
使用numpy模块进行读写操作
Python第三方库numpy提供loadtetxt()函数进行读取操作,要求文件各行数据数量相同
利用numpy模块的loadtxt()函数读取CSV文件内容时需要列名预处理等比较复杂
的操作,一般不推荐使用。
loadtxt(filepath,dtype="float",delimiter=None,skiprows=0,usecols=None)
filepath 指定加载文件路径及文件名
dtype 指定返回的数据类型,默认为float
delimiter 字符串类型可选参数,指定加载文件中数据的分隔符,默认是空格
skiprows 指定文件中不需要读取的行数;
usecols 元组类型可选参数,指定加载文件中特定列的索引,默认读取所有列
提供savetxt()函数进行写入操作
savetxt(filepath,data,delimiter,fmt)
data 要写入的数据
delimiter 保存到CSV文件的数据间隔符
fmt 写入的数据格式
import numpy as np #导入模板
filename = '/path/filename.csv' #文件路径
with open(filename,"r") as f
col_name_str = f.readline()[:-1] #获得文件首行除去'\n'的列名字符串
col_name_list = col_name_str.split(',') #将字符串转换成列表
use_col_name_list = […………] #想要的列表名
data_array = np.loadtxt(filename,delimiter=',',skiprows=1,dtype=str,useclos=use_col_name_list) # 从文件中获得想要的数据
type(data_array) # numpy.ndarray
np.savetxt('/new.csv',data_array, delimiter=',',fmt = '%s') #将读取到的数据存储至新CSV
使用pandas模块进行读写操作
Python第三方库pandas也提供简单的CSV文件读写函数,返回一个DataFrame类型的数据对象。利用pandas处理CSV文件快捷方便,也是常用的CSV文件读写方式。
①读操作:
pandas模块提供了用于读取CSV文件内容的pandas.read_csv()函数,该函数快速而直接地打开、读取并分析CSV文件,并将数据存储在DataFrame对象中。
pandas模块自动识别CSV文件第一行列名。如果第一行没有列名,可添加参数names提供列名。同时忽略现有列名或覆盖列名,需要使用参数header=0
此外,pandas模块的DataFrame对象具有从零开始的整数索引。如果需要使用CSV文件中其他列作为DataFrame对象的索引,可以在pandas.read csv()函数中添加可选参数index_col
②写操作:
使用pandas.to_csv()函数将DataFrame对象写入CSV文件
import pandas as pd #导入pandas模板
filename = '/path/filename.csv'
df = pd.read_csv(filename,index_col = "?",header = 0,names=[…………]) # 读取文件数据
print(df) #打印
df.to_csv('/path/new.csv',index = False) # 保存至新文件(不包含索引)
网络数据获得
网络爬虫简介
网络爬虫(web spider)又称网络机器人、网络蜘蛛,是一种根据既定规则,自动提取网页信息的程序或者脚本,传统爬虫以一个或若干初始网页的统一资源定位符(Uniform Resource Location,URL)为起点,下载每一个URL指定的网页分析并获取页面内容,并不断从当前页面抽取新的URL放入队列,记录每一个已经爬取过的页面,直到URL队列为空或满足设定的停止条件为止。
按照系统结构和实现技术,网络爬虫大致分为四种类型,实际应用中的网络爬虫系统通常是几种爬虫技术相结合实现的
网络爬虫分类:
- 通用网络爬虫(GeneraPurpose Web Crawler)又称全网爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据
- 深度优先爬行策略:按照深度由低到高的顺序,依次访问下一级网页链接,直到不能再深入为止。爬虫在完成一个爬行分支后返回上一个链接节点进一步搜索其它链接
- 广度优先爬行策略:按照网页内容目录层次深浅来爬行页面,优先爬取目录层次较浅的页面。当同一层次的页面爬行完毕,再深入下一层次继续爬取
- 聚焦网络爬虫(FocusedWeb Crawler )又称主题网络爬虫,它会选择性地爬取与预定主题相关的页面
- 基于内容评价的爬行策略
- 基于链接结构的搜索策略
- 基于增强学习的爬行策略
- 基于语境图的爬行策略
- 增量式网络爬虫(Incremental Web Crawler),对已下载的网页采取增量式更新策略,只爬行新产生或已经发生变化的网页,在一定程度上保证爬行尽可能新的页面
- 统一更新法:爬虫以相同的频率访问所有网页,不考虑网页的改变频率
- 个体更新法:爬虫根据个体网页的改变频率重新访问各页面
- 基于分类的更新法:爬虫根据网页改变频率分为更新较快网页子集和更新较慢网页子集两类,然后以不同的频率访问这两类网页
- 深层网络爬虫(DeepWeb Crawler),Web页面按照存在方式可以分为表层网页和深层网页两类。表层网页是指传统搜索引擎可以索引到的页面,以超链接可以到达的静态网页为主。深层网页是指隐藏在搜索表单后,大部分内容不能通过静态链接获取,只有用户提交关键词才能获得的Web页面。深层网页是目前互联网上最大、发展最快的新型信息资源深层网页爬中爬行过程中最重要的部分就是表单填写,表单填写方法可以分为两类
- 基于领域知识的表单填写
- 基于网页结构分析的表单填写
网络爬虫任务:主要完成两个任务,即下载目标网页和从目录网页中解析信息
网络爬虫基本架构
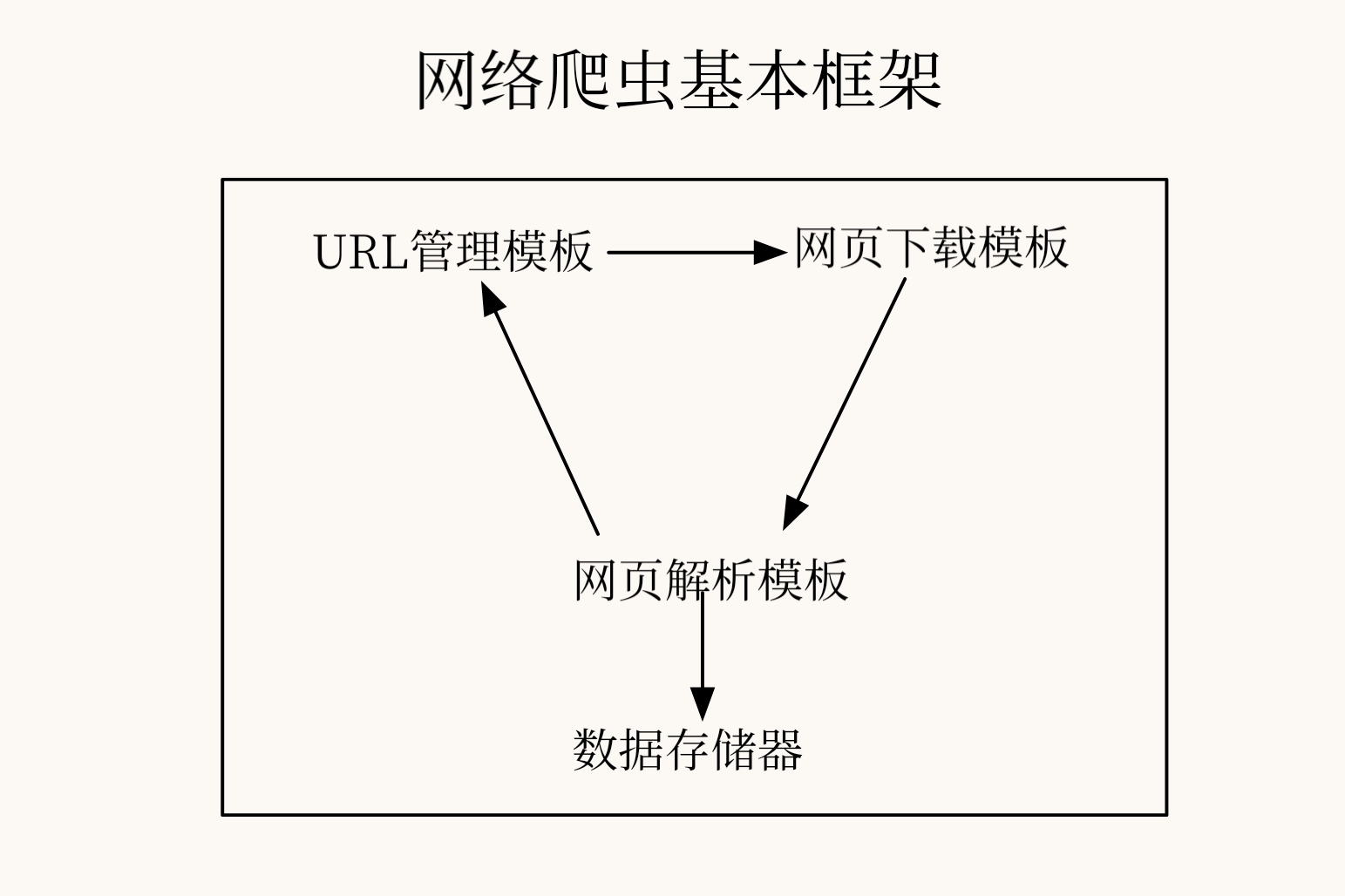
- URL管理模板:添加新的URL链接、管理已爬行的URL和未爬行的URL以及获取待爬行的URL
- 网页下载模板:用于从URL管理模块中将指定URL对应的页面下载到本地,或者以字符串形式读入内存,方便后续使用字符串相关操作解析网页内容
- 网页分析模板:用于从网页下载模块获取已下载的网页,并解析出有效数据交给数据存储器
- 数据存储器:负责将网页解析模块解析出的数据存储起来,用于后续的数据分析和信息利用
网页下载模块
requests库:是Python中一个处理HTTP请求的第三方库
requests库的网页请求
| 函数 | 说明 |
| get(url[,timeout = n]) | 对应HTTP的GET方式, 可选参数timeout设定每次请求超时时间,单位为秒 |
| post(url,data={‘key’: ‘value’}) | 对应HTTP的POST方式, 其中字典用于传递客户数据 |
| put(url,data={‘key’: ‘value’}) | 对应HTTP的PUT方式, 其中字典用于传递客户数据 |
| delete(url) | 对应HTTP的DELETE方式 |
| head(url) | 对应HTTP的HEAD方式 |
| options(url) | 对应HTTP的OPTIONS方式 |
response对象:调用网页请求方法后,返回的网页内容保存为一个response对象
response对象常见属性
| 属性 | 说明 |
| status_code | HTTP请求返回的状态码,为整数 |
| headers | HTTP相应内容的网页header信息 |
| encoding | HTTP响应内容的编码形式 |
| text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| content | HTTP响应内容的二进制形式 |
在调用请求方法后,可以使用response.status_code属性返回HTTP请求状态,如果请求状态未被响应,需要中止内容处理
- 为response.encoding属性赋值可以改变编码方式,便于处理中文字符
- 除了属性,response对象也提供了一些方法response.json(),可以解析HTTP响应内容中的JSON格式数据;response.raise_for_status(),如果状态码不是“200”,则会抛出异常
import requests
def getHTMLText(url)
try:
r_obj = requests.get(url)
r_obj = raise_for_status()
r_obj.encoding = 'utf-8'
return r_obj.text
except:
return ""
url = "http://www.datazzh.top"
print(getHTMLText(url))
网页解析模块
beautifulsoup4库:Python第三方库,用于解析和处理HTML、xml文件并提取数据
作为第三方库需要预先安装,在Python解释器中导入使用
pip install beautifulsoup4 #命令窗口中安装库 from bs4 import Beautifulsoup #解释器中导入模组
文档对象模型:一个网页文件通常可以表示一个文档对象模型(DOM),DOM是一种处理HTML、XML文件的标准编程接口,将网页文档表示为一个树形结构,每一个节点表示一个HTML标签(tag)或标签内的文本项
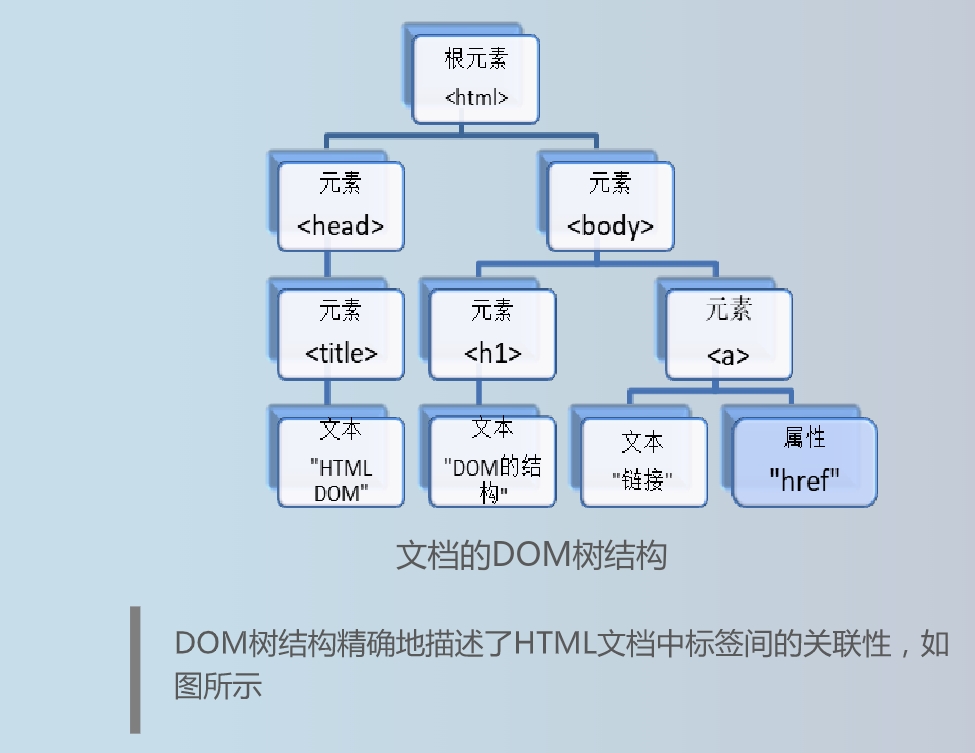
将HTML或XML文档转化为DOM树的过程称为解析
HTML 文档被解析后,转化为DOM树,因此对HTML文档的处理可以通过对DOM树的操作实现
导入bs4库的BeautifulSoup类之后,使用BeautifulSoup()创建一个BeautifulSoup对象。实例化的BeautifulSoup对象相当于一个页面,表示一个文档的全部内容